高級編程語言提供的函數、條件語句和循環這樣的抽象編程構造極大地提高了編程效率。然而,這也潛在地使性能顯著下降成為了用高級編程語言寫程序的一大劣勢。在理想條件下,在不以性能為妥協的情況下,你應該寫出易讀并且易維護的代碼。因此,編譯器嘗試自動優化代碼以提高其性能,當今的編譯器都深諳其道。編譯器可以轉化循環、條件語句和遞歸函數、消除整塊代碼和利用目標指令集的優勢讓代碼變得高效而簡潔。所以對程序員來說,寫出可讀性高的代碼要比因為手工優化而使代碼變得神秘且難以維護更加可貴。事實上,手工優化的代碼反而可能會讓編譯器難以進行額外和更加有效的優化。
比起手工優化代碼,你更應該考慮關于設計的各個方面,比如使用更快的算法,引入線程級并行機制和利用框架特性(比如move構造函數)。
這篇文章是關于Visual C++ 編譯器優化的。為了便于應用,我將會討論編譯器采取的最重要的優化技巧和決策。我的目的不是告訴你如何手工優化代碼,而是向你展示為什么你可以信賴編譯器來優化你寫出的代碼。這篇文件絕不是對Visual C++ 編譯器優化工作的全面考察。但是將會給你展示那些你真正想要了解的優化工作和怎樣與你的編譯器溝通來應用它們。
有一些重要的優化是超出所有現有編譯器能力的——比如,用高效的算法代替低效的,或者改變數據結構的排列以優化其在內存中的布局。但是這些優化話題超出了本文的范圍。
定義編譯器優化
優化工作涉及到的一個方面,是把一行代碼轉化成同等效果的另一行代碼,在這個過程中提升它的一項或多項性能。最重要的兩項性能(指標)是代碼的執行速度和長度。其他一些特性包括代碼執行開銷,代碼編譯所需時間,如果代碼需要通過即時編譯機制(Just-in-Time (JIT))進行編譯,那么JIT所需的編譯時間也是指標之一。
編譯器經常會依據它們所使用的技術優化代碼。雖然并不完美,但是比起花時間手工苦苦推敲一個程序,利用編譯器提供的特有功能和讓編譯器來優化代碼要高效得多。
這里有4種方法讓你的編譯器更加高效地優化代碼:
書寫可讀、高效的代碼。不要把Visual C++ 面向對象的特性當作性能的敵人。最新版本的C++可以讓這些開銷保持到最低甚至消除這些開銷。
2.使用編譯器聲明。例如讓編譯器使用比默認情況更快的函數調用約定。
3.使用編譯器內置函數(compiler-intrinsic functions)。內在函數是其實現由編譯器自動提供的特殊函數。編譯器對其很熟悉并且會用極其高效的指令序列來代替函數調用,以充分利用目標指令集的優勢。當前Microsoft .NET Framework不支持編譯器內置函數,因此其下的語言都不支持。但是Visual C++ 對這一特性有外在支持。注意,雖然使用內置函數能夠提升代碼性能,但是會降低可讀性和可移植性。
4. 使用性能分析引導優化(profile-guided optimization)。使用這一技術,可以讓編譯器搜集更多關于代碼的運行時行為,并且以此來作為優化依據。
本文的目的是通過證明編譯器可以在低效但是可讀性強的代碼上應用優化(應用第一條方法),從而向你展示為什么你可以信任編譯器。當然我也會提供一些對性能分析引導優化(profile-guided optimization)的簡短說明,和提到一些可以微調代碼的編譯器聲明。
編譯器有許多優化技巧,從像常量折疊這樣簡單的變換,直到像指令重排(instruction scheduling)這樣極其復雜的變換。然而在這篇文章中我只有限地討論了一些最重要的優化——那些可以顯著地提升性能(兩位數的百分數來衡量)和減少代碼長度的優化:內聯函數(function inlining)、COMDAT優化(COMDAT optimizations)和循環優化。我將會在下一部分討論前兩個話題,然后展示你如何控制Visual C++實現優化。最后會有.NET Framework優化的簡略說明。通篇我都將會采用Visual Studio 2013來構建代碼。
鏈接時代碼生成
鏈接時代碼生成(LTCG)是一項應用在C/C++代碼上的程序全局優化(WPO)技術。C/C++編譯器獨立地編譯每個源文件然后產生出相應的目標文件。這意味著編譯器只能在單個源文件上應用優化技術,而無法照顧到整個程序。但是,一些重要的優化卻只能瀏覽全部程序后才能產生。所以你只能在鏈接時(link time)應用這些優化,而非編譯時(compile time),因為鏈接器可以完整地看到程序。
當LTGC被打開時(通過指定編譯器開關/GL),編譯器驅動程序(cl.exe)將只調用編譯器前端(c1.dll or c1xx.dll),并把后端調用(c2.dll)推遲到鏈接時間。產出的目標文件包含通用中間語言(Common Intermediate Language——CIL)代碼,而不是依賴機器的匯編代碼。然后,當鏈接器(link.exe)被調用,它就能看到包含C中間語言的目標文件,并調用編譯器后端,依次進行程序全局優化,生成二進制目標文件,再返回鏈接器把所有目標文件鏈接在一起,最后生成可執行文件。
編譯器前端實際上進行了一些優化,比如無論優化啟用還是禁用,都會進行常量折疊。但是所有重要的優化工作都是在編譯器后端進行的,并且可以使用編譯器開關控制。
鏈接時代碼生成(LTCG)能讓后端積極地執行許多優化(通過指定/GL與/O1或/O2,以及/Gw編譯器開關,和/OPT:REF 與 /OPT:ICF鏈接器開關)。在本文中,討論僅限于內聯函數(function inlining)和COMDAT優化(COMDAT optimizations)。關于完整的鏈接時代碼生成優化,請參考相關文檔。注意鏈接器可以在本地目標文件,本地/托管混合目標文件,純托管目標文件,安全托管目標文件和安全.net模塊上執行鏈接時代碼生成。
我編寫了一個包含兩個源文件(source1.c 和 source2.c)和一個頭文件(source2.h)的程序。source1.c 和 source2.c分別在Figure 1 and Figure 2中。由于頭文件中非常簡單地包含了source2.c中的函數原型, 所以并沒有列出。
Figure 1 The source1.c File
#include <stdio.h> // scanf_s and printf.
#include "Source2.h"
int square(int x) { return x*x; }
main() {
int n = 5, m;
scanf_s("%d", &m);
printf("The square of %d is %d.", n, square(n));
printf("The square of %d is %d.", m, square(m));
printf("The cube of %d is %d.", n, cube(n));
printf("The sum of %d is %d.", n, sum(n));
printf("The sum of cubes of %d is %d.", n, sumOfCubes(n));
printf("The %dth prime number is %d.", n, getPrime(n));
}
Figure 2 The source2.c File
#include <math.h> // sqrt.
#include <stdbool.h> // bool, true and false.
#include "Source2.h"
int cube(int x) { return x*x*x; }
int sum(int x) {
int result = 0;
for (int i = 1; i <= x; ++i) result += i;
return result;
}
int sumOfCubes(int x) {
int result = 0;
for (int i = 1; i <= x; ++i) result += cube(i);
return result;
}
static
bool isPrime(int x) {
for (int i = 2; i <= (int)sqrt(x); ++i) {
if (x % i == 0) return false;
}
return true;
}
int getPrime(int x) {
int count = 0;
int candidate = 2;
while (count != x) {
if (isPrime(candidate))
++count;
}
return candidate;
}
source1.c文件包含兩個函數,有一個參數并返回這個參數的平方的square函數,以及程序的main函數。main函數調用source2.c中除了isPrime之外的所有函數。source2.c有5個函數。cube返回一個數的三次方;sum函數返回從1到給定數的和;sumOfcubes返回1到給定數的三次方的和;isPrime用于判斷一個數是否是質數;getPrime函數返回第x個質數。我省略掉了容錯處理因為那并非本文的重點。
這些代碼簡單但是很有用。其中一些函數只進行簡單的運算,一些需要簡單的循環。getPrime是當中最復雜的函數,包含一個while循環且在循環內部調用了也包含一個循環的isPrime函數。我將會利用這些函數證實被稱作內聯函數的優化,和一些其他的優化,其中內聯函數這是編譯器最重要的優化之一。
我會在三種不同的配置下生成代碼并且檢驗結果來驗證代碼是如何被編譯器轉化的。如果你也照做的話,你需要匯編生成文件(由編譯器開關/FA[s]生成)來檢驗生成的匯編代碼以及映像文件(由鏈接器開關/MAP生成)來檢驗初始化數據優化是否被執行(如果你指定了/verbose:icf 和 /verbose:ref開關,鏈接器也可以匯報這一項)。因此你需要確保在接下來的配置中指定了上述開關。我也會使用C編譯器(/TC)以讓生成的代碼容易檢驗。但是這篇文章中所有我討論的東西對于C++一樣適用。
Debug配置
之所以使用Debug配置,是因為在你打開了編譯器/Od開關而沒有打開/GL開關時,所有的后端優化都是禁用的。當在這項配置下構建代碼時,生成的目標文件將包含和源代碼完全對應的二進制代碼。你可以通過生成的匯編輸出文件和映像文件來確認這一點。這項配置相當于Visual Studio中的調試配置。
編譯時代碼生成Release配置
這項配置和優化被啟用的配置(通過指定/O1,/O2或/Ox編譯器開關)非常相似,但是不指定/GL編譯器開關。在這項配置下,生成目標文件將包含優化過的二進制代碼。但是沒有整個程序級別的優化。
通過查看source1.c生成的匯編代碼文件,你會看到執行了兩項優化。首先,通過在編譯時的評估計算把square函數的第一次調用完全刪去了。這是如何發生的呢?編譯器發現square函數很小,它應該被作為內聯函數。將它作為內聯函數之后,編譯器發現本地變量n的值是已知的并且在給它賦值和調用函數之間沒有發生改變。因此,編譯器總結出執行乘法和用25替代結果是安全的。第二項優化,對于square的第二次調用square(m),也被當作內聯函數。但是,因為m的值在編譯時是未知的,所以編譯器不能對計算估值,所以事實上代碼被保留了。
現在我會檢查source2.c的匯編代碼文件,這將會更有趣。在函數sumOfCubes內對cube的調用被作為內聯函數。這會讓編譯器啟用了對循環來說意義重大的一些優化(如你在“循環優化”部分將看到的)。此外,SSE2指令集被用于在isPrime函數中,當調用了sqrt函數時把int轉化為double而在sqrt返回值時又把double轉化為int。并且sqrt只在循環開始前調用了一次。注意如果/arch編譯器開關沒有被打開,x86編譯器將會默認使用SSE2。大多數x86處理器以及所有x86-64處理器,都支持SSE2。
鏈接時代碼生成Release配置
鏈接時代碼生成(LTCG) Relase配置與Visual Studio中的Release配置相同。在這項配置中,優化被啟用并且/GL編譯器開關被打開。這個開關隱含的指定了使用/O1或者/O2。這告訴編譯器生成通用中間語言(Common Intermediate Language——CIL)目標文件而不是匯編目標文件。這樣,鏈接器像之前所說那樣調用編譯器的后端來執行整個程序的優化。現在我將會討論一些程序全局優化來展示鏈接時代碼生成帶來的巨大好處。這項配置所生成的匯編代碼列表可以在網絡上得到。
只要允許函數被內聯(/Ob控制,不論何時,只要需要優化就可以打開),不論/Gy開關(稍后討論)是否打開,/GL開關都允許把其他翻譯單元中定義的函數作為內聯函數。/LTCG鏈接器開關是可選的并且只為鏈接器提供指導。
通過查看source1.c的匯編代碼,你會看到除了scanf_s之外的所有函數都被作為了內聯函數。因此,編譯器被允許執行函數cube,sum和sunOfCubes的計算。只有isPrime函數沒有被作為內聯函數。但是,如果它被我們手動在getPrime中寫為內聯函數,編譯器仍然會在main函數中把getPrime作為內聯函數。
正如你所見,將函數內聯很重要不僅僅是因為它總是優化函數調用,而且它可以允許編譯器進行許多其他優化。將函數內聯通常會以代碼量增加為代價來提升性能。過度地使用這一優化會導致我們熟知的代碼膨脹現象。在每一次調用函數的地方,編譯器都會分析這樣做的利弊來決定是否將一個函數作為內聯函數。
由于內聯的重要性,Visual C++編譯器提供了比對內聯的標準規定控制更多的支持。你可以通過使用auto_inline編譯控制編譯器不將一段范圍內的函數內聯。你可以通過標記為__declspec(noinline)控制編譯器不把特定的函數或方法內聯。你可以用關鍵字inline標記一個函數來給編譯器提示將這個函數作為內聯函數(雖然編譯器可能選擇忽略這一標記如果這次內聯帶來的是凈損失)。inline關鍵字從C++的第一個版本——C99,就可以使用了。你可以同時在C或者C++中使用微軟特有的關鍵字_inline,這在你使用不支持inline的老式C版本時是很有用的。并且,你可以使用__forceinline關鍵字(C和C++)來強制編譯器將任何可以內聯的函數內聯。最后但是很重要的一點是,你可以告訴編譯器以確定或者不確定的深度拆開一個遞歸函數,這可以通過使用inline_recursion編譯指令來達成。注意編譯器當下沒有提供任何特性可以讓你在函數調用時控制內聯,一切都只能在函數定義時控制。
默認情況下生效的/Ob0開關會完全禁用內聯功能。你應該在調試代碼時使用這一開關(它在Visual Studio Debug配置下是自動打開的)。/Ob1開關讓編譯器只在函數被定義為inline,__inline 或者__forceinline時,才考慮將函數內聯。/Ob2開關在指定了/O[1|2|x]時生效,編譯器將會考慮所有的函數是否可以內聯。在我看來,只有在/Ob1控制內聯時考慮是否使用inline或_inline才是有意義的。
在一些特定的條件下,編譯器是不能將函數內聯的。舉個例子,當虛調用一個虛函數時,因為編譯器不知道哪個函數將會被調用,所以這個函數不能被內聯。另一個例子是當通過指針調用一個函數而不是通過函數名時。你應該盡力避免這些條件來使得函數可以被內聯。具體請參考MSDN文檔,那里列出了不能被內聯的完整條件列表。
某些優化,當其作用于整個程序級別時,往往比其作用于局部時更加有效,函數內聯就是這種類型的優化之一。事實上,大多數優化都在整體級別更加有效。在這一部分余下的內容中,我將會討論被稱作COMDAT優化的一類特定優化。
默認情況下,當編譯翻譯單元時,所有的代碼都被存儲到結果目標文件的一個單獨區塊。鏈接器在單獨區塊的范疇上進行操作:也就是對這些區塊進行移除、合并或者重新排序。(但是)這種會妨礙鏈接器進行三項優化工作,而這三項優化工作對顯著減少可執行代碼量和提升性能又非常重要。第一項是消除未被引用的函數和全局變量;第二項是合并相同的函數和全局常量;第三項是重新對函數和全局變量排序,使得那些在同一路徑上執行的函數和被一起訪問的變量在物理內存中離得更近,這會讓程序有更好的局部性。
為了能讓這些鏈接器優化生效,你可以通過分別打開/Gy(函數級別鏈接)和/Gw(全局數據優化)來分別讓編譯器對位于在不同區塊的函數和變量進行打包操作。這些區塊被稱為COMDATs。你也可以用__declspec( selectany)標記特定的全局數據變量來告訴編譯器把這個變量加入COMDAT。然后,通過指定/OPT:REF鏈接器開關,鏈接器就會刪去未被引用的函數和全局變量。你也可以通過指定/OPT:ICF開關,鏈接器就會合并相同的函數和全局常數變量。(ICF代表Identical COMDAT Folding。)通過/ORDER鏈接器開關,你可以讓鏈接器把COMDAT以特定的順序放入生成鏡像。注意所有的這些優化都是鏈接器優化所以不需要/GL開關。如果是要對程序進行調試,并且目的明確,那么/OPT:REF和/OPT:ICF開關應當關閉。
你應該盡可能使用鏈接時代碼生成(LTCG)。唯一不使用的原因是當你想要分發生成的目標文件和二進制文件時。記得這些文件包含通用中間語言(CIL)而不是匯編語言,通用中間語言只能被生成它的特定版本的編譯器和鏈接器識別,這將會明顯限制目標文件的使用,因為開發者必須使用相同版本的編譯器以使用這些文件。這種情況下,除非你愿意為每個版本的編譯器都分發一份目標文件,否則你應該使用編譯時代碼生成。除了限制使用,這些目標文件通常比相應的匯編目標文件更加龐大。但是記得CIL目標文件帶來的巨大好處,那就是可以進行程序全局優化(WPO)。
循環優化
Visual C++支持多種循環優化,但是我只討論其中的3種:循環展開,自動向量化和循環不變量代碼移動。如果你修改了Figure1中的代碼讓m代替n作為sumOfCubes的參數,編譯器將不能推斷出參數的值,所以必須讓函數可以處理任何參數。生成函數被高度優化并且尺寸很大,所以編譯器不會將它作為內聯函數。
用/O1生成匯編代碼,會在空間尺寸上進行優化。在這種情況下,不會對sumOfCubes函數實行任何優化操作。用/O2生成代碼針對執行速度進行優化。生成代碼的長度會很長但是執行效率顯著提高,因為sumOfCubes內部的循環被展開并且向量化了。有一個概念很重要,必須理解:如果不把cube函數內聯就不能進行向量化。而且,不進行內聯的話循環展開并不會變得高效。Figure3 顯示了生成的匯編代碼的流程圖。這個流程圖對x86和x86-64架構都適用。
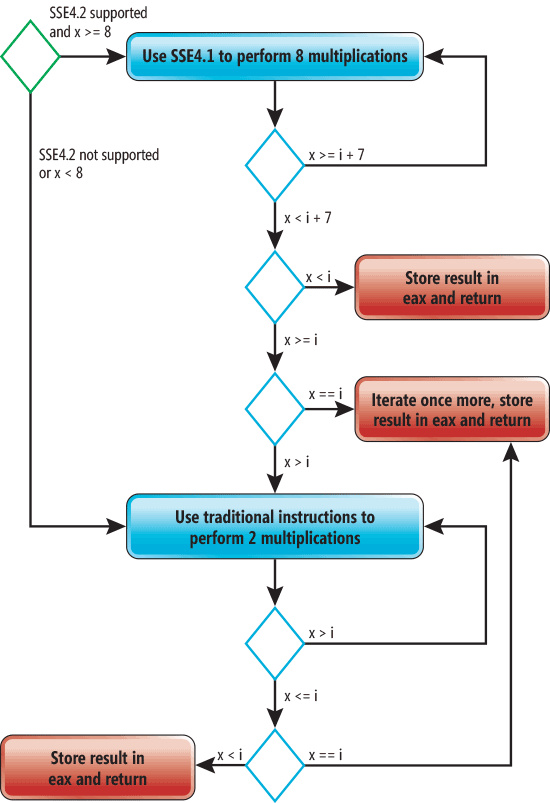
圖3 sumOfCubes流程圖
在Figure3中,綠色的菱形代表開始點,紅色矩形代表結束點。藍色菱形代表在運行時作為sumOfCubes函數中一部分而被執行的條件。如果處理器支持SSE4并且x大于等于8,就會使用SSE4指令同時執行四個乘法指令。同時把同一操作在多個值上執行的過程被稱為向量化。編譯器也會將循環展開,就是說循環體將會把每次迭代循環重復一次。這樣做的最終效果就是八次乘法在每次迭代都會被執行。當x的值小于8時,傳統的指令將會被用于執行余下的運算。注意到編譯器放出了結合了三個獨立結尾的循環結束點而不是一個。這將會減少跳轉次數。
循環展開是重復執行循環體的過程,展開后的循環每次把未展開循環內的循環體執行不止一次。這樣做的原因是可以通過減少循環控制指令的執行頻率來提升性能。也許更重要的是,這樣可以允許編譯器進行許多其他優化工作,比如向量化。循環展開的弊端是會增加代碼量和寄存器的壓力。但是這可能使性能達到兩位百分數級別的提升,當然這是和具體的循環體有關的。
不同于x86處理器,所有的x86-64處理器都支持SSE2.不僅如此,你可以在最新的x86-64微處理器架構上(包括Intel和AMD)通過打開/arch開關來利用AVX/AVX2指令集。打開/architecture:AVX2也會允許編譯器使用FMA和BMI指令集。
當前的Visual C++編譯器不支持控制循環展開。但是你可以通過使用模版結合__ forceinline關鍵字來模仿這一技術。你可以通過使用no_vector選項來禁用對于某個函數的自動向量化。
通過觀察生成的匯編代碼,如果你有足夠敏銳的眼睛的話你會注意到代碼還有少許優化空間。但是,編譯器已經做了很多工作了,并且不會再花更多的時間分析代碼和進行一些無關緊要的優化。
SumOfCubes(原文是someOfCubes,應該是寫錯了——譯者注)不是唯一一個循環被展開的函數。如果你修改代碼讓m作為參數而不是n,編譯器將不能對代碼進行估計,因此必須放出其代碼。在這種情況下,循環被展開了兩次。
最后我要討論的優化是循環不變量代碼移動(loop-invariant code motion)。考慮如下代碼:
int sum(int x) {
int result = 0;
int count = 0;
for (int i = 1; i <= x; ++i) {
++count;
result += i;
}
printf("%d", count);
return result;
}
這里唯一的改變是增加了一個變量并且在每次循環進行自增,然后打印。不難看出這段代碼可以通過把變量count的自增移出循環來優化。也就是說,我可以直接把x的值賦給變量count。這種優化被稱為循環不變量代碼移動(loop-invariant code motion)。循環不變量部分清楚的表明這項技術只能用于其代碼不依賴于任何循環之前的表達式的情況。
那么這里有一個問題:如果你自己來進行這項優化,生成的代碼可能在某些情況下會導致性能下降。能發現為什么嗎?考慮x為非正數的情況。循環將不被執行,這意味著未被手動優化的代碼中count不會被訪問。但是,在我們手動優化過的代碼中在循環外進行了一次不必要的賦值操作,把x賦給了count。更甚者,如果x是負數,count就會擁有錯誤的值。程序員和編譯器都容易受到這種陷阱的影響。所幸Visual C++編譯器足夠聰明地在賦值之前加上了循環條件,這樣可以對所有x的值都生成性能有所提升的代碼。
綜上所述,如果你既不是編譯器也不是編譯器優化方面的專家,你應該避免僅僅因為想讓代碼更快而進行手工修改。管住你的手并且相信編譯器將會優化你的代碼。
控制優化
除了/O1,/O2,和/Ox編譯開關,你還可以使用控制優化編譯來達到讓某個函數優化的目的,其形式如下:
#pragma optimize( "[optimization-list]", {on | off} )
[optimization-list]可以為空或者一個或多個緊跟的值:g,s,t和y。分別對應編譯器開關/Og,/Os,/Ot和/Oy.
空列表和off參數會讓所有的優化都被關閉,不管之前的編譯器開關是否被打開。空列表和on參數會讓之前打開的編譯器開關生效。
/Og開關啟用全局優化,全局優化只作用域那些通過表面分析就可以被優化的函數上,而這些函數內部調用的其他函數則不會被優化。如果(鏈接時代碼生成)LTCG被啟用,/Og允許代碼全局優化(WPO)。
當你需要讓不同的函數進行不同的優化時,比如一些進行空間尺寸優化而另一些進行執行速度優化,那么優化編譯參數就很有用了。但是如果真的想達到那種粒度的控制,你應該考慮性能分析引導優化(PGO),就是通過對運行測量代碼時的行為信息進行記錄,然后使用這一紀錄對代碼進行優化的過程。編譯器使用性能分析來決定怎樣優化代碼。Visual Studio提供了必要的工具,來將這一技術同時應用于本機代碼和托管代碼上。
.NET中的優化
在.NET的編譯模型中沒有鏈接器。但是有一個源代碼編譯器(C# compiler)和即時編譯器(JIT compiler),源代碼編譯器只進行很小的一部分優化。比如它不會執行函數內聯和循環優化。而這些優化是由即時編譯器執行的。在4.5以前的所有.NET Framework JIT都不支持SIMD指令集。但是.NET Framework 4.5.1和之后的版本都裝有支持SIMD的即時編譯器,被稱為RyuJIT。
從優化能力上來講RyuJIT和Visual C++有什么不同呢?因為RyuJIT是在運行時完成其工作的,所以它可以完成一些Visual C++不能完成的工作。比如在運行時,RyuJIT可能會判定,在這次程序的運行中一個if語句的條件永遠不會為true,所以就可以將它移除。RyuJIT也可以利用他所運行的處理器的能力。比如如果處理器支持SSE4.1,即時編譯器就會只寫出sumOfCubes函數的SSE4.1指令,讓生成打的代碼更加緊湊。但是它不能花更多的時間來優化代碼,因為即時編譯所花的時間會影響到程序的性能。另一方面,Visual C++編譯器可以花更多的時間尋找和利用更多恰當的優化機會。微軟新推出了一項稱為.NET Native的全新技術,允許你使用Visual C++編譯器后端對托管代碼(Managed Code)進行編譯和優化,并形成自包含的獨立可執行程序。當下這項技術只支持Windows Store apps。
在當前控制托管代碼的能力是很有限的。C#和VB編譯器只允許使用/optimize編譯器開關打開或者關閉優化功能。為了控制即時編譯優化,你可以在方法上使用System.Runtime.CompilerServices.MethodImpl屬性和MethodImplOptions中指定的選項。NoOptimization選項可以關閉優化,NoInlining阻止方法被內聯,AggressiveInlining (.NET 4.5)選項推薦(不僅僅是提示)即時編譯器將一個方法內聯。
結語
本文中提到的所有優化功能都會顯著地將你的代碼效率提升兩位百分數級別,并且Visual C++編譯器支持所有這些優化。重要的是這些技術能夠在應用之后,帶來其他更多的優化。本文絕不敢奢望能夠對Visual C++編譯器的優化工作進行一次綜合全面的討論。但是我希望通過本文可以讓你領會編譯器的精妙。Visual C++可以做比這多得多的事情,所以敬請期待Part2。
更多信息請查看IT技術專欄