為什么要有緩存
應用需要離線工作的主要原因就是改善應用所表現出的性能。將應用內容緩存起來就可以支持離線。我們可以用兩種不同的緩存來使應用離線工作。第一種是**按需緩存**,這種情況下應用緩存起請求應答,就和Web瀏覽器的工作原理一樣;第二種是**預緩存**,這種情況是緩存全部內容(或者最近n條記錄)以便離線訪問。
像第14章中開發的Web服務應用利用按需緩存技術來改善可感知的性能而不是提供離線訪問。離線訪問只是無心插柳的結果。Twitter和Foursquare就是很好的例子。這類應用得到的數據通常很快就會過時。對于一條幾天前的推文或者朋友上周在哪里你能有多大興趣?一般來說,一條推文或者一條簽到的信息只在幾個小時內有意義,而24小時之后就變得無關緊要。不過大部分Twitter客戶端還是會緩存推文,而Foursquare的官方客戶端在無網絡連接的情況下打開,會顯示上次的狀態。
大家可以用自己喜歡的Twitter客戶端來試一下,Twitter for iPhone、Tweetbot或其他應用:打開某個朋友的個人資料并瀏覽他的時間線。應用會獲取時間線并填充頁面。加載時間線時會看到一個表示正在加載的圓圈在旋轉。現在進入另一個頁面,然后再回來打開時間線。你會發現這次是瞬間加載的。應用還是在后臺刷新內容(在上次打開的基礎上),但是它會顯示上次緩存的內容而不是無趣地轉圈,這樣看起來就快多了。如果沒有緩存,用戶每次打開一個頁面都會看到圓圈在旋轉。無論網絡連接快還是慢,減小網絡加載慢的影響,讓它看起來很快,是iOS開發者的責任。這就能大大改善用戶滿意度,從而提高了應用在App Store中的評分。
另一種緩存更加重視被緩存數據,并且能快速編輯被緩存的記錄而無需連接到服務器。代表應用包括Google Reader客戶端,稍后閱讀類的應用Instapaper等。
緩存的策略:
上一節中討論到按需緩存和預緩存,它們在設計和實現上有很大的不同。按需緩存是指把從服務器獲取的內容以某種格式存放在本地文件系統,之后對于每次請求,檢查緩存中是否存在這塊數據,只有當數據不存在(或者過期)的情況下才從服務器獲取。這樣的話,緩存層就和處理器的高速緩存差不多。獲取數據的速度比數據本身重要。而預緩存是把內容放在本地以備將來訪問。對預緩存來說,數據丟失或者緩存不命中是不可接受的,比方用戶下載了文章準備在地鐵上看,但卻發現設備上不存在這些文章。
像Twitter、Facebook和Foursquare這樣的應用屬于按需緩存,而Instapaper和Google Reader等客戶端則屬于預緩存。
實現預緩存可能需要一個后臺線程訪問數據并以有意義的格式保存,以便本地緩存無需重新連接服務器即可被編輯。編輯可能是“標記記錄為已讀”或“加入收藏”,或其他類似的操作。這里**有意義的格式**是指可以用這種方式保存內容,不用和服務器通信就可以在本地作出上面提到的修改,并且一旦再次連上網就可以把變更發送回服務器。這種能力和Foursquare等應用不同,雖然使用后者你能在無網絡連接的情況下看到自己是哪些地點的地主(Mayor),當然前提是進行了緩存,但無法成為某個地點的地主。Core Data(或者任何結構化存儲)是實現這種緩存的一種方式。
按需緩存工作原理類似于瀏覽器緩存。它允許我們查看以前查看或者訪問過的內容。按需緩存可以通過在打開一個視圖控制器時按需地緩存數據模型(創建一個數據模型緩存)來實現,而不是在一個后臺線程上做這件事。也可以在一個URL請求返回成功(200 OK)應答時實現按需緩存(創建一個URL緩存)。兩種方法各有利弊,稍后我會在24.3節和24.6節中解釋各個方法的優缺點。
選擇使用按需緩存還是預緩存的一個簡便方法是判斷是否需要在下載數據之后處理數據。后期處理數據可能是以用戶產生編輯的形式,也可能是更新下載的數據,比如重寫HTML頁面里的圖片鏈接以指向本地緩存圖片。如果一個應用需要做上面提到的任何后期處理,就必須實現預緩存。
存儲緩存:
第三方應用只能把信息保存在應用程序的沙盒中。因為緩存數據不是用戶產生的,所以它應該被保存在NSCachesDirectory,而不是NSDocumentsDirectory。為緩存數據創建獨立目錄是一項不錯的實踐。在下面的例子中,我們將在Library/caches文件夾下創建名為MyAppCache的目錄。可以這樣創建:
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSCachesDirectory,
NSUserDomainMask, YES);
NSString *cachesDirectory = [paths objectAtIndex:0];
cachesDirectory = [cachesDirectory
stringByAppendingPathComponent:@"MyAppCache"];
把緩存存儲在緩存文件夾下的原因是iCloud(和iTunes)的備份不包括此目錄。如果在Documents目錄下創建了大尺寸的緩存文件,它們會在備份的時候被上傳到iCloud并且很快就用完有限的空間(寫作本書時大約為5 GB)。你不會這么干的——誰不想成為用戶iPhone上的良民?NSCachesDirectory正是解決這個問題的。
預緩存是用高級數據庫(比如原始的SQLite)或者對象序列化框架(比如Core Data)實現的。我們需要根據需求認真選擇不同的技術。本節第5點“應該用哪種緩存技術”給出了一些建議:什么時候該用URL緩存或者數據模型緩存,而什么時候又該用Core Data。接下來先看一下數據模型緩存的實現細節。
1. 實現數據模型緩存
可以用NSKeyedArchiver類來實現數據模型緩存。為了把模型對象用NSKeyedArchiver歸檔,模型類需要遵循NSCoding協議。
NSCoding協議方法
- (void)encodeWithCoder:(NSCoder *)aCoder; - (id)initWithCoder:(NSCoder *)aDecoder;
當模型遵循NSCoding協議時,歸檔對象就很簡單,只要調用下列方法中的一個:
[NSKeyedArchiver archiveRootObject:objectForArchiving
toFile:archiveFilePath];
[NSKeyedArchiver archivedDataWithRootObject:objectForArchiving];
第一個方法在archiveFilePath指定的路徑下創建一個歸檔文件。第二個方法則返回一個NSData對象。NSData通常更快,因為沒有文件訪問開銷,但對象保存在應用的內存中,如果不定期檢查的話會很快用完內存。在iPhone上定期緩存到閃存的功能也是不明智的,因為跟硬盤不同,閃存讀寫壽命是有限的。開發者得盡可能平衡好兩者的關系。24.3節會詳細介紹歸檔實現緩存。
NSKeyedUnarchiver類用于從文件(或者NSData指針)反歸檔模型。根據反歸檔的位置,選擇使用下面兩個類方法。
[NSKeyedUnarchiver unarchiveObjectWithData:data];
[NSKeyedUnarchiver unarchiveObjectWithFile:archiveFilePath];
這四個方法在轉化序列化數據時能派上用場。
使用任何NSKeyedArchiver/NSKeyedUnarchiver的前提是模型實現了NSCoding協議。不過要做到這一點很容易,可以用Accessorizer類工具自動實現NSCoding協議。(24.8節列出了Accessorizer在Mac App Store中的鏈接。)
下一節會解釋預緩存策略。我們剛才已經了解到預緩存需要用到更結構化的數據格式,接下來看看Core Data和SQLite。
2. Core Data
正如Marcus Zarra所說,Core Data更像是一個對象序列化框架,而不僅僅是一個數據庫API:
大家誤認為Core
Data是一個Cocoa的數據庫API……其實它是個可以持久化到磁盤的對象框架(Zarra,2009年)。
要深入理解Core Data,看一下Marcus S. Zarra寫的*Core Data: Apple's API for Persisting Data on Mac OS X*(Pragmatic Bookshelf, 2009. ISBN 9781934356326)。
要在Core Data中保存數據,首先創建一個Core Data模型文件,并創建實體(Entity)和關系(Relationship);然后寫好保存和獲取數據的方法。應用可以借助Core Data獲取真正的離線訪問功能,就像蘋果內置的Mail和Calendar應用一樣。實現預緩存時必須定期刪除不再需要的(過時的)數據,否則緩存會不斷增長并影響應用的性能。同步本地變更是通過追蹤變更集并發送回服務器實現的。變更集的追蹤有很多算法,我推薦的是Git版本控制系統所用的(此處沒有涉及如何與遠程服務器同步緩存,這不在本書討論范圍之內)。
3. 用Core Data實現按需緩存
盡管從技術上講可以用Core Data來實現按需緩存,但我不建議這么做。Core Data的優勢是不用反歸檔完整的數據就可以獨立訪問模型的屬性。然而,在應用中實現Core Data帶來的復雜度抵消了優勢。此外,對于按需緩存實現來說,我們可能并不需要獨立訪問模型的屬性。
4. 原始的SQLite
可以通過鏈接libsqlite3的庫來把SQLite嵌入應用,但是這么做有很大的缺陷。所有的sqlite3庫和對象關系映射(Object Relational Mapping,ORM)機制幾乎總是會比Core Data慢。此外,盡管sqlite3本身是線程安全的,但是iOS上的二進制包則不是。所以除非用定制編譯的sqlite3庫(用線程安全的編譯參數編譯),否則開發者就有責任確保從sqlite3讀取數據或者往sqlite3寫入數據是線程安全的。Core Data有這么多特性而且內置線程安全,所以我建議在iOS中盡量避免使用SQLite。
唯一應該在iOS應用中用原始的SQLite而不用Core Data的例外情況是,資源包中有應用程序相關的數據需要在所有應用支持的第三方平臺上共享,比如說運行在iPhone、Android、BlackBerry和Windows Phone上的某個應用的位置數據庫。不過這也不是緩存了。
5. 應該用哪種緩存技術
在眾多可以本地保存數據的技術中,有三種脫穎而出:URL緩存、數據模型緩存(利用NSKeyedArchiver)和Core Data。
假設你正在開發一個應用,需要緩存數據以改善應用表現出的性能,你應該實現按需緩存(使用數據模型緩存或URL緩存)。另一方面,如果需要數據能夠離線訪問,而且具有合理的存儲方式以便離線編輯,那么就用高級序列化技術(如Core Data)。
6. 數據模型緩存與URL緩存
按需緩存可以用數據模型緩存或URL緩存來實現。兩種方式各有優缺點,要使用哪一種取決于服務器的實現。URL緩存的實現原理和瀏覽器緩存或代理服務器緩存類似。當服務器設計得體,遵循HTTP 1.1的緩存規范時,這種緩存效果最好。如果服務器是SOAP服務器(或者實現類似于RPC服務器或RESTful服務器),就需要用數據模型緩存。如果服務器遵循HTTP 1.1緩存規范,就用URL緩存。數據模型緩存允許客戶端(iOS應用)掌控緩存失效的情形,當開發者實現URL緩存時,服務器通過HTTP 1.1的緩存控制頭控制緩存失效。盡管有些程序員覺得這種方式違反直覺,而且實現起來也很復雜(尤其是在服務器端),但這可能是實現緩存的好辦法。事實上,MKNetworkKit提供了對HTTP 1.1緩存標準的原生支持。
數據模型緩存:
本節我們來給第14章中的iHotelApp添加用數據模型緩存實現的按需緩存。按需緩存是在視圖從視圖層次結構中消失時做的(從技術上講,是在viewWillDisappear:方法中)。支持緩存的視圖控制器的基本結構如圖24-1所示。AppCache Architecture的完整代碼可從本章的下載源代碼中找到。后面講解的內容假設你已經下載了代碼并且可以隨時使用。
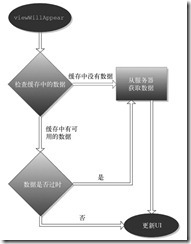
圖24-1
實現了按需緩存的視圖控制器的控制流
在viewWillAppear方法中,查看緩存中是否有顯示這個視圖所需的數據。如果有就獲取數據,再用緩存數據更新用戶界面。然后檢查緩存中的數據是否已經過期。你的業務規則應該能夠確定什么是新數據、什么是舊數據。如果內容是舊的,把數據顯示在UI上,同時在后臺從服務器獲取數據并再次更新UI。如果緩存中沒有數據,顯示一個轉動的圓圈表示正在加載,同時從服務器獲取數據。得到數據后,更新UI。
前面的流程圖假定顯示在UI上的數據是可以歸檔的模型。在iHotelApp的MenuItem模型中實現NSCoding協議。NSKeyedArchiver需要模型實現這個協議,如下面的代碼片段所示。
MenuItem類的encodeWithCoder方法(MenuItem.m)
- (void)encodeWithCoder:(NSCoder *)encoder
{
[encoder encodeObject:self.itemId forKey:@"ItemId"];
[encoder encodeObject:self.image forKey:@"Image"];
[encoder encodeObject:self.name forKey:@"Name"];
[encoder encodeObject:self.spicyLevel forKey:@"SpicyLevel"];
[encoder encodeObject:self.rating forKey:@"Rating"];
[encoder encodeObject:self.itemDescription forKey:@"ItemDescription"];
[encoder encodeObject:self.waitingTime forKey:@"WaitingTime"];
[encoder encodeObject:self.reviewCount forKey:@"ReviewCount"];
}
MenuItem類的initWithCoder方法(MenuItem.m)
- (id)initWithCoder:(NSCoder *)decoder
{if ((self = [super init])) {
self.itemId = [decoder decodeObjectForKey:@"ItemId"];
self.image = [decoder decodeObjectForKey:@"Image"];
self.name = [decoder decodeObjectForKey:@"Name"];
self.spicyLevel = [decoder decodeObjectForKey:@"SpicyLevel"];
self.rating = [decoder decodeObjectForKey:@"Rating"];
self.itemDescription = [decoder
decodeObjectForKey:@"ItemDescription"];
self.waitingTime = [decoder decodeObjectForKey:@"WaitingTime"];
self.reviewCount = [decoder decodeObjectForKey:@"ReviewCount"];
}return self;
}
就像之前提到過的,可以用Accessorizer來生成NSCoding協議的實現。
根據圖24-1中的緩存流程圖,我們需要在viewWillAppear:中實現實際的緩存邏輯。把下面的代碼加入viewWillAppear:就可以實現。
視圖控制器的viewWillAppear:方法中從緩存恢復數據模型對象的代碼片段
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSCachesDirectory,
NSUserDomainMask, YES);
NSString *cachesDirectory = [paths objectAtIndex:0];
NSString *archivePath = [cachesDirectory
stringByAppendingPathComponent:@"AppCache/MenuItems.archive"];
NSMutableArray *cachedItems = [NSKeyedUnarchiver
unarchiveObjectWithFile:archivePath];if(cachedItems == nil)
self.menuItems = [AppDelegate.engine localMenuItems];else
self.menuItems = cachedItems;
NSTimeInterval stalenessLevel = [[[[NSFileManager defaultManager]
attributesOfItemAtPath:archivePath error:nil]
fileModificationDate] timeIntervalSinceNow];if(stalenessLevel > THRESHOLD)
self.menuItems = [AppDelegate.engine localMenuItems];
[self updateUI];
緩存機制的邏輯流如下所示。
視圖控制器在歸檔文件MenuItems.archive中檢查之前緩存的項并反歸檔。
如果MenuItems.archive不存在,視圖控制器調用方法從服務器獲取數據。
如果MenuItems.archive存在,視圖控制器檢查歸檔文件的修改時間以確認緩存數據有多舊。如果數據過期了(由業務需求決定),再從服務器獲取一次數據。否則顯示緩存的數據。
接下來,把下面的代碼加入viewDidDisappear方法可以把模型(以NSKeyedArchiver的形式)保存在Library/Caches目錄中。
視圖控制器的viewWillDisappear:方法中緩存數據模型的代碼片段
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSCachesDirectory,
NSUserDomainMask, YES);
NSString *cachesDirectory = [paths objectAtIndex:0];
NSString *archivePath = [cachesDirectory stringByAppendingPathComponent:@" AppCache/MenuItems.archive"];
[NSKeyedArchiver archiveRootObject:self.menuItems toFile:archivePath];
視圖消失時要把menuItems數組的內容保存在歸檔文件中。注意,如果不是在viewWillAppear:方法中從服務器獲取數據的話,這種情況不能緩存。
所以,只需在視圖控制器中加入不到10行的代碼(并將Accessorizer生成的幾行代碼加入模型),就可以為應用添加緩存支持了。
重構
當開發者有多個視圖控制器時,前面的代碼可能會有冗余。我們可以通過抽象出公共代碼并移入名為AppCache的新類來避免冗余。AppCache是處理緩存的應用的核心。把公共代碼抽象出來放入AppCache可以避免viewWillAppear:和viewWillDisappear:中出現冗余代碼。
重構這部分代碼,使得視圖控制器的viewWillAppear/viewWillDisappear代碼塊看起來如下所示。加粗部分顯示重構時所做的修改,我會在代碼后面解釋。
視圖控制器的viewWillAppear:方法中用AppCache類緩存數據模型的重構代碼片段(MenuItemsViewController.m)
-(void) viewWillAppear:(BOOL)animated {
self.menuItems = [AppCache getCachedMenuItems];
[self.tableView reloadData];if([AppCache isMenuItemsStale] || !self.menuItems) {
[AppDelegate.engine fetchMenuItemsOnSucceeded:^(NSMutableArray *listOfModelBaseObjects) {
self.menuItems = listOfModelBaseObjects;
[self.tableView reloadData];
} onError:^(NSError *engineError) {
[UIAlertView showWithError:engineError];
}];
}
[super viewWillAppear:animated];
} -(void) viewWillDisappear:(BOOL)animated {
[AppCache cacheMenuItems:self.menuItems];
[super viewWillDisappear:animated];
}
AppCache類把判斷數據是否過期的邏輯從視圖控制器中抽象出來了,還把緩存保存的位置也抽象出來了。稍后在本章中我們還會修改AppCache,再引入一層緩存,內容會保存在內存中。
因為AppCache抽象出了緩存的保存位置,我們就不需要為復制粘貼代碼來獲得應用的緩存目錄而操心了。如果應用類似于iHotelApp,開發者可通過為每個用戶創建子目錄即可輕松增強緩存數據的安全性。然后我們就可以修改AppCache中的輔助方法,現在它返回的是緩存目錄,我們可以讓它返回當前登錄用戶的子目錄。這樣,一個用戶緩存的數據就不會被隨后登錄的用戶看到了。
完整的代碼可以從本書網站上本章的源代碼下載中獲取。
緩存版本控制:
我們在上一節中寫的AppCache類從視圖控制器中抽象出了按需緩存。當視圖出現和消失時,緩存就在幕后工作。然而,當你更新應用時,模型類可能會發生變化,這意味著之前歸檔的任何數據將不能恢復到新的模型上。正如之前所講,對按需緩存來說,數據并沒有那么重要,開發者可以刪除數據并更新應用。我會展示可以用來在版本升級時刪除緩存目錄的代碼片段。
iOS中驗證模型:
第二個是驗證模型,服務器通常會發送一個校驗和(Etag)。后續所有從緩存獲得資源的請求都應該用這個校驗和向服務器**重新驗證**資源是否有變化。如果校驗和匹配,服務器就返回一個HTTP 304 Not Modified的狀態碼。
IOS內存緩存:
目前為止,所有iOS設備都帶有閃存,而閃存有點小問題:它的讀寫壽命是有限的。盡管這個壽命跟設備的使用壽命比起來很長,但是仍然需要避免過于頻繁地讀寫閃存。在上一個例子中,視圖隱藏時是直接緩存到磁盤的,而視圖顯示時又是直接從磁盤讀取的。這種行為會使用戶設備的緩存負擔很重。為避免這個問題,我們可以再引入一層緩存,利用設備的RAM而不是閃存(用NSMutableDictionary)。在24.2.1節的“實現數據模型緩存”中,我們介紹了創建歸檔的兩種方法:一個是保存到文件,另一個是保存為NSData對象。這次會用到第二個方法,我們會得到一個NSData指針,將該指針保存到NSMutableDictionary中,而不是文件系統里的平面文件。引入內存緩存的另一個好處是,在歸檔和反歸檔內容時性能會略有提升。聽起來很復雜,實際上并不復雜。本節將介紹如何給AppCache類添加一層透明的、位于內存中的緩存。(“透明”是指調用代碼,即視圖控制器,甚至不知道這層緩存的存在,而且也不需要改動任何代碼。)我們還會設計一個LRU(Least Recently Used,最近最少使用)算法來把緩存的數據保存到磁盤。
以下簡單列出了要創建內存緩存需要的步驟。這些步驟將會在下面幾節中詳細解釋。
添加變量來存放內存緩存數據。
限制內存緩存大小,并且把最近最少使用的項寫入文件,然后從內存緩存中刪除。RAM是有限的,達到使用極限就會觸發內存警告。收到警告時不釋放內存會使應用崩潰。我們當然不希望發生這種事,所以要為內存緩存設置一個最大閾值。當緩存滿了以后再添加任何東西時,最近最少使用的對象應該被保存到文件(閃存中)。
處理內存警告,并把內存緩存以文件形式寫入閃存。
當應用關閉、退出,或進入后臺時,把內存緩存全部以文件形式寫入閃存。
更多信息請查看IT技術專欄